
31·
1 month agoWhat drawbacks?
What drawbacks?

Your Gemini is way funnier in my opinion. I think he actually might have set up a trap for himself by asking it to produce what the LLM would consider a typical or average reply. Whereas by asking it to just make a short, funny comment, you’re actually getting results that feel more natural.
For Gemini, only the first and last one read weird to me. But I think I would just assume that I’m missing some context to get the jokes, or something.
Whereas the actual replies from the OP actually reek of standard LLM drivel. The way it is trying so hard to sound casual and cool, but coming across as super awkward is just classic GPT.
At the same time, I feel like we shouldn’t let that happen because imagine if he actually succeeds? And then we just have immortal crackhead Lex Luthor with a hallucinating ChatGPT whispering further delusions directly into his brain. That can’t be good for any of us.
You should note that this was a Gmail feature that is now made available by a bunch of email providers, but you might wanna check that you do indeed get your emails delivered to plus addresses before you rush out to change your contact info everywhere. Some providers have lacking support and sometimes emails may fail to send to plus addresses even if your side does support it. Using a catchall will always work because you know, that’s just how email works.
It is definitely the exact opposite of this. Even though I understand why you would think this.
The thing with systems like these is they are mission critical, which is usually defined as failure = loss of life or significant monetary loss (like, tens of millions of dollars).
Mission critical software is not unit tested at all. It is proven. What you do is you take the code line by line, and you prove what each line does, how it does it, and you document each possible outcome.
Mission critical software is ridiculously expensive to develop for this exact reason. And upgrading to deploy on different systems means you’ll be running things in a new environment, which introduces a ton of unknown factors. What happens, on a line by line basis, when you run this code on a faster processor? Does this chip process the commands in a slightly different order because they use a slightly different algorithm? You don’t know until you take the new hardware, the new software, and the code, then go through the lengthy process of proving it again, until you can document that you’ve proven that this will not result in any unusual train behavior.
I’ve thought of it many times and it hasn’t helped me for shit
I haven’t been paying attention to Hyundai, what did they do?
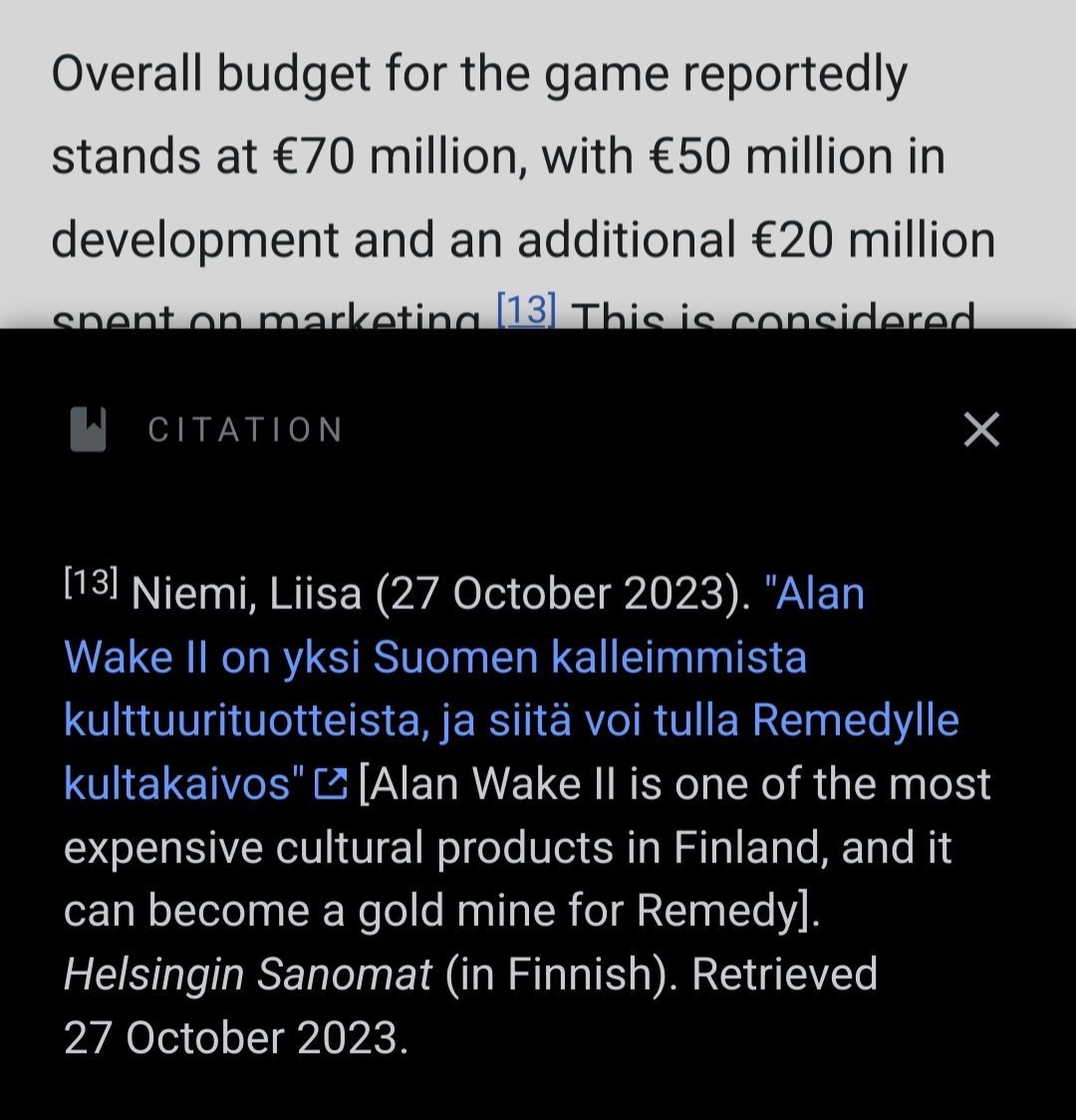
Oh yeah no that was a typo, that budget is for Alan Wake 2 - its on the Alan Wake 2 wikipedia page, sourcing a Finnish newspaper at the time of writing this comment.
https://en.m.wikipedia.org/wiki/Alan_Wake_2
Alan Wake is pretty much the definition of a modern AA game, though, so that just plays into what he’s saying.
While Alan Wake 2 is super well executed, its development costs is dwarfed by modern triple A games that cost at least 10 times more to develop.
(Alan Wake 2 reported budget 50-70 million euro, compared to games like Assassin’s Creed Valhalla, Red Dead Redemption 2 or Cyberpunk 2077 which were all reported at ~500 million euro, while games like MW3 (2023) and GTA VI both have billion dollar+ budgets).
“Patch notes: fixed weird bug slowing down the expansion of the universe; heat death now correctly occurs in 2025”
Well, shit
Why would he pay for something that’s free…?
Minimalist design really went from “maybe 38 different clickable links isn’t the most optimal way to get around this site, we should probably optimize how we use screen space” to “WE MUST GET RID OF USEFUL FEATURES SO WE CAN DISPLAY 5-8 MORE PIXELS OF WHITESPACE” in the span of a decade lol
Yes I am aware of that. However, I’m not sure how this has anything to do with the fact that it is also illegal to steal data, then continue to use said data to make profits after having been found out. The two are not connected in any logical way, which makes it hard for me to continue to address your concerns in a way that makes sense.
The way I see it, you’re either completely missing what we’re talking about, or you have some misunderstanding of what the AI language models actually are, and what they can do.
For the record, I’m in no way disagreeing with your views, or your statements that legal and ethical don’t always overlap. It is clear to me that you are open minded and well-intended, which I appreciate, and I hope you don’t take this the wrong way.
You seem to think the majority of LGBT+ positive material is somehow illegal to obtain. That is not the case. You can feed it as much LGBT+ positive material as you like, as long as you have legally obtained it. What you can’t do is train it on LGBT+ positive material that you’ve stolen from its original authors. Does that make more sense?
No, especially because it’s not the same thing at all. You’re talking about the output, we’re talking about the input.
The training data was illegally obtained. That’s all that matters here. They can train it on fart jokes or Trump propaganda, it doesn’t really matter, as long as the Trump propaganda in question was legally obtained by whoever trained the model.
Whether we should then allow chatbots to generate harmful content, and how we will regulate that by limiting acceptable training data, is a much more complex issue that can be discussed separately. To address your specific example, it would make the most sense that the chatbot is guided towards a viewpoint that aligns with its intended userbase. This just means that certain chatbots might be more or less willing to discuss certain topics. In the same way that an AI for children probably shouldn’t be able to discuss certain topics, a chatbot that’s made for use in highly religious area, where homosexuality is very taboo, would most likely not be willing to discuss gay marriage at all, rather than being made intentionally homophobic.
If there’s something illegal in your dish, you throw it out. It’s not a question. I don’t care that you spent a lot of time and money on it. “I spent a lot of time preparing the circumstances leading to this crime” is not an excuse, neither is “if I have to face consequences for committing this crime, I might lose money”.
We need a second third party HR team to investigate OUR third party HR team, and make sure they stand up to scrutiny!
Well, incidentally, porn bots. And he doesn’t want to lose them, too!